
Monitoring von Websites und Webshops
![]() 22.03.2016 (Bearbeitet am 18.10.2021) von Matthias
22.03.2016 (Bearbeitet am 18.10.2021) von Matthias

Das Wort „Überwachung“ ist häufig mit negativen Gefühlen behaftet. Dabei kann Überwachung auch gut sein. Zum Beispiel, wenn jemand Ihre Website oder Ihren Webshop überwacht und somit sicherstellt, dass Probleme so früh wie möglich erkannt und behoben werden. Ähnlich wie bei der menschlichen Gesundheit sollte man sich proaktiv um die Gesundheit seines Web-Projekts kümmern. Wir sprechen in diesem Fall von Monitoring bzw. Website-Monitoring und im heutigen Beitrag konkret vom Kontrollieren der technischen Aspekte einer Site.
Wie werden Websites überwacht?
Sie haben sicher gleich erkannt dass es ineffizient wäre, das Monitoring manuell durchzuführen. Dabei handelt es sich um eine mühsame, fehleranfällige und aufwändige Arbeit. Das wiederum ist eine wunderschöne Definition für etwas, was man gerne als automatisierte Aufgabe einem Computer zur Abarbeitung umhängt.
Um diese Automatisierung einführen zu können muss man Regeln definieren
- welche Aspekte einer Website, eines Webshops, Webservices etc.
- wann und wie häufig
- auf welche Weise
überprüft werden.
Was wird überwacht?
Je nach Art des Projekts lassen sich diverse Parameter unter die Lupe nehmen.
Auf Hardware-Ebene ist zum Beispiel überprüfbar wie stark Server ausgelastet sind, was CPU, RAM oder Speicherbedarf angeht. Ebenso können Fehler-Raten für Netzwerk-, Festplatten-Zugriffe etc. Hinweise darauf geben, wenn Hardware-Komponenten zu versagen drohen. Auf diese Dinge ein Auge zu haben ist primär Aufgabe des Providers, vor allem wenn wie bei uns üblich „Managed Hosting“ zum Einsatz kommt. Trotzdem monitoren wir bei Bedarf gerne selbst die erstgenannten Parameter: wenn hier der Zeiger in den roten Bereich geht, ist häufig eine schnelle Reaktion gefragt und da hilft die Verkürzung der Wege natürlich.
Ebenso gilt es, auf Software-Ebene nach dem Rechten zu sehen. Diverse Checks bieten einen Einblick in die Operationalität des Projekts:
- Größe von Log-Tabellen/-Files
- Größe von Error-Logs/-Files
- Größe sowie Hit-Rate von Caches
- Anzahl und Entwicklung von User-Sessions
- Werden Cronjobs ausgeführt?
- Wann wurde der letzte Cronjob ausgeführt?
- Läuft ein Cronjob länger als geplant?
- Ist die Website erreichbar?
- Wie schnell lädt die Website?
Wichtig sind nicht nur die aktuellen Werte, sondern zeitliche Veränderungen. Nimmt kurz nachdem Änderungen vorgenommen worden sind die Anzahl an Fehlern oder die Auslastung des Servers zu, ist das ein Indiz dass Nachbesserungsbedarf besteht.
Nicht zuletzt ist die Gesundheit auf Projekt-Ebene zu beurteilen. Hierbei handelt es sich um Aspekte der jeweiligen Software bzw. des jeweiligen Projekts, die regelmäßig getestet werden sollen:
- Wann ging die letzte Bestellung ein?
- Ist das Kontaktformular in Ordnung?
- Existiert eine Google-Sitemap?
- Existiert eine robots.txt-Datei?
- Werden alle Bilder-, Datei-Caches richtig erzeugt?
- Verarbeitet die Schnittstelle die Anfragen ohne Fehler?
In den Aufgabenbereich des Monitorings fallen jene funktionalen und inhaltlichen Punkte, die nicht nur einmalig bei Änderungen sondern tatsächlich ständig überwacht werden sollen. Das sind meistens die kritischsten Teile der Website.
Natürlich gibt es abseits des technischen Monitorings in anderen Domänen noch viele Dinge mehr, die überprüfenswert sind – zum Beispiel wenn wir im Zuge der Suchmaschinen-Optimierung laufend das Ranking einer Site für verschiedene Keywords oder im E-Commerce die Konversions-Rate eines Webshops verfolgen möchten. Lassen Sie uns wissen, wenn Sie dazu mehr lesen möchten!
Wie werden die Ergebnisse des Monitorings verwertet?
Nachdem es wiederum mühsam, fehleranfällig und aufwändig wäre, die Ausgaben des Monitorings manuell durchzusehen und auf ihren Handlungsbedarf hin zu überprüfen, lässt man auch das den Computer übernehmen. Das bezeichnen wir als Alerting.
Wenn die Monitoring-Software die Werte erhoben hat entscheidet sie aufgrund vorbestimmter Richtlinien, was zu tun ist. Üblicherweise werden Schwellenwerte definiert wann etwas „in Ordnung“ ist, wann eine „Warnung“ gemeldet werden muss und ab wann die Angelegenheit „kritisch“ wird. Die Warnung dient dazu, frühzeitig auf eine Entwicklung aufmerksam zu machen. Häufig muss hier nicht sofort reagiert werden sondern es reicht, den Punkt im Auge zu behalten. Der Status „kritisch“ wird erwartungsgemäß dann ausgegeben, wenn man sich aktiv mit der Situation auseinandersetzen sollte.
Welche Software kommt für das Monitoring zum Einsatz?
Wir setzen auf eine Kombination von Services und entscheiden gemeinsam mit dem Kunde, welche Tools und welche Checks für das Projekt geeignet sind.
Auf der einen Seite stehen SaaS-Dienste („Software as a Service“) von externen Anbietern, die solche Dienste auf ihrer eigenen Plattform anbieten.
Es handelt sich hier um spezialisierte Tools wie das insgesamt eher einfach gehaltene Pingdom, welches die Verfügbarkeit Ihrer Website („Ist die Seite erreichbar?“) sowie die Ladezeit regelmäßig aus bis zu 60 verschiedenen Lokationen überprüft.
Teurere Alternativen wie New Relic bieten neben Server- und Application-Monitoring auf Verfügbarkeit tiefgreifende Einblicke in die Auslastung und Performance der Systeme. Wann sich der Einsatz dieser Anbieter lohnt, hängt häufig von der restlichen Systemlandschaft, den Vor-Erfahrungen und dem Budget des Kunden ab.
Auf der anderen Seite steht lokale Monitoring-Software, die wir auf unserer eigenen Infrastruktur betreiben. Wir können hier wesentlich flexibler agieren und bestimmen, was wir wann auf welche Weise überprüfen.
Unser Tool der Wahl ist das Open-Source-System Icinga.
Icinga
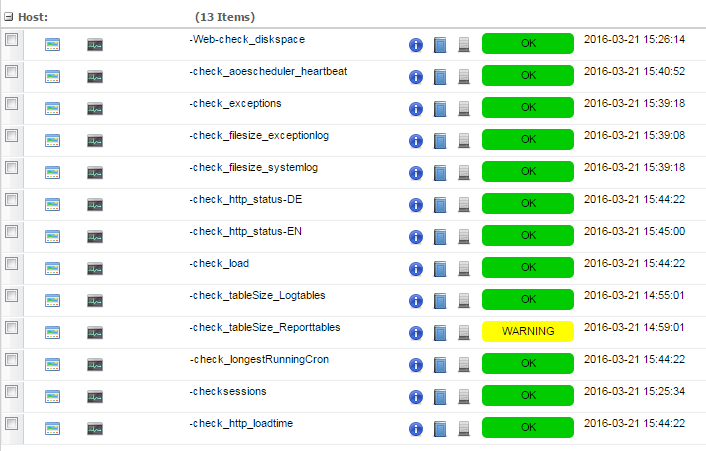
Obwohl es sich bei Icinga um eine lizenzkostenfreie Open-Source-Software handelt, ist sie absolut Enterprise-tauglich und wird von Unternehmen wie Audi, Adobe oder CERN eingesetzt.
Mit Icinga können wir sowohl öffentliche als auch nicht-öffentliche Installationen auf die oben genannten Parameter untersuchen. Ebenso können wir nach Bedarf neue Checks erstellen, die Abfragehäufigkeiten verändern oder die Schwellenwerte feintunen, um uns auf das jeweilige System einzustellen.
Im ersten Screenshot sieht man, dass alle Checks erst kürzlich ausgeführt wurden und mit Ausnahme der Überprüfung der Magento-Report-Tabellen einen OK-Status zurücklieferten. Der reporttables-Check informiert uns darüber, dass die Größe der Report-Tabellen einen von uns definierten Schwellenwert überschritten hat. Hier besteht für uns kein unmittelbarer Handlungsbedarf, doch wir erhalten eine Warn-Mail und erstellen ein Ticket in unserem Issue-Tracker um demnächst zu überprüfen, ob die Größe dieser Tabelle reduziert werden kann. So wird sichergestellt, dass die Daten in der Tabelle nicht unnötig Festplatten-Platz und Speicherbereiche im RAM einnehmen oder Laufzeiten für die Erstellung von Datenbank-Sicherungen und das eventuelle Einspielen alter Datenbank-Backups („Rollback“) verlängern.
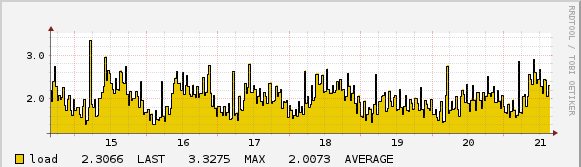
Pro Check kann über Eskalations-Stufen definiert werden, wer wann auf welche Seite wie informiert wird. Ein fiktiver Alarmierungs-Plan könnte so aussehen, dass ein Warning ausgelöst wird, wenn die CPU-Auslastung des Servers (siehe zweiter Screenshot) innerhalb von 15 Minuten drei-mal über dem vordefinierten Schwellenwert von 6 liegt. In diesem Fall wird der Tech-Lead des Projekts per E-Mail informiert werden. Reagiert er innerhalb der Arbeitszeit nicht innerhalb von 15 Minuten auf die Warnung, dann kann die Mail mit höherer Dringlichkeit an den Tech-Lead sowie den Project-Lead geschickt werden. Wer will, kann dies bei Nicht-Beachtung beliebig weiter eskalieren lassen bis hin zum 5-minütigen Versand der Meldung an alle Techniker und Geschäftsführer per SMS und Posts in den firmen-internen Slack-Channels.
Fazit
Mit Tools wie Icinga oder New Relic können wir sicherstellen, dass die Server unserer Webshops und Websites fit sind und in den Systemen alles wie erwartet funktioniert. Während SaaS-Anbieter für bestimmte Szenarien erweiterte Funktionen bereitstellen, bietet sich Icinga als flexibles Allround-Werkzeug für fast jeglichen erdenklichen Gesundheits-Check an.
Kombiniert man Monitoring und Alerting, wird man frühzeitig auf negative Entwicklungen aufmerksam gemacht und kann in vielen Fällen eingreifen, bevor es für Besucher und Betreiber zu spürbaren Einschränkungen kommt.



Kommentare
Hallo Matthias,
danke für den Artikel. Die „Sahnehaube“ obendrauf sind dann noch End2End-Checks, bei denen die Oberfläche einer Applikation automatisiert getestet wird – so wie es der End User macht. Wir haben dafür ein plattformunabhängiges Framework namens „Sakuli“ (Open Source) entwickelt, welches die Tools Sahi (für Web-Tests) und Sikuli (für Bild-Pattern-basierte Oberflächentests) kombiniert. Seit Version 1.0 kann Sakuli Test-Ergebnisse auch an die REST API von Icinga2 schicken.
Alarme gibt es dann z.B. wenn ein bestimmter Teilschritt (z.B. Login) oder der ganze Test zu lange dauert, oder ein Element (Link, Bild, Text etc…) nicht gefunden werden kann. Sakuli läuft auch in Docker-Containern.
Code & Doku: https://github.com/ConSol/sakuli
Hier ein Code-Beispiel, wie der OXID eShop von Sakuli geprüft wird: https://github.com/ConSol/sakuli-examples/blob/master/oxid_ubuntu/oxid/oxid_case.js
vg Simon
Hallo Simon, danke für deine Antwort! End2End-Checks laufen bei uns unter dem Thema „Automatisiertes Testen“ und sind ebenfalls sehr wichtig. Ich finde es gut, dass ihr das in Icinga integriert habt. Somit kann der CI-Server während der Entwicklung bei fehlgeschlagenen Frontend-Tests warnen und Icinga bei Produktiv-Systemen. Wir werden das im Auge behalten!
Danke für den Beitrag, ich finde es immer schön zu wissen, was der Rest der Welt so nutzt zum monitoren. Ich möchte den Beitrag gerne noch um eine Facette erweitern:
Wir haben durch unseren Hoster (MaxCluster) die Empfehlung zu Tideways bekommen. Dort hat man wenn Fehler Auftreten gleich noch die Möglichkeit, zu sehen in welcher Zeile in welcher Datei der Fehler aufgetreten ist und in der Regel gibt es auch Stacktraces dazu. Außerdem kann man via Chrome-Extension ein Profiling der Live deployten Installation ausführen ohne dass merkbar die Performance leidet.
Hi Tobi, danke für den Hinweis. Von Tideways habe ich auch schon von einigen Gutes gehört. Dasselbe gilt für Blackfire.io und um noch eine weitere Alternative zu nennen bewirbt Ruxit gerade seine Dienste intensiv. :-)